Залізний Гаррі – професійний інструментарій для монтажу та обслуговування кабельних систем!
Після того, як мережі були вивернуті навиворіт несподіваним збільшенням дистанційної роботи, організації стали більш уразливі до успішного проникнення. Коли ми стикаємося з потенційно серйозною загрозою, очевидно, що нам потрібно зробити найменшу кількість кроків і витратити на це якомога менше часу, щоб ефективно і швидко перейти від виявлення до реагування. Яким би очевидним це не здавалося, багато на власному досвіді дізнаються, що наявні інструменти та процеси не завжди відповідають цьому бажанню.
Чому? У багатьох випадках мова йде просто про необхідність збирати великі обсяги необроблених даних, не маючи відповідної можливості отримувати вибірки, які могли б бути перетворені в відповіді.
Підхід, який часто використовується, полягає в тому, щоб узагальнити ці великі обсяги необроблених даних в якісь усереднені метадані. Звичайно, бувають ситуації, коли це дуже корисно, але бувають і такі, коли буквально кожен біт інформації необхідний для того, щоб відтворити подію або зрозуміти її наслідки. Отже, що ж нам залишається? Як нам вивести на поверхню корисну інформацію, не відкидаючи критично важливі деталі, які можуть знадобитися для розслідування?
Давайте розглянемо приклад тієї ролі, яку може зіграти правильний робочий процес у вирішенні цієї задачі.
Крок 1: Виявлення аномальної активності
Знання того, як повинні поводити себе наші хости або пристрої, має дозволити нам швидко зрозуміти, коли вони поводять себе не так. У цьому прикладі з карти загроз верхнього рівня ми бачимо, що у нас є HR сервер, який раптово почав брати участь в сесіях, що не входять в його стандартний профіль поведінки.
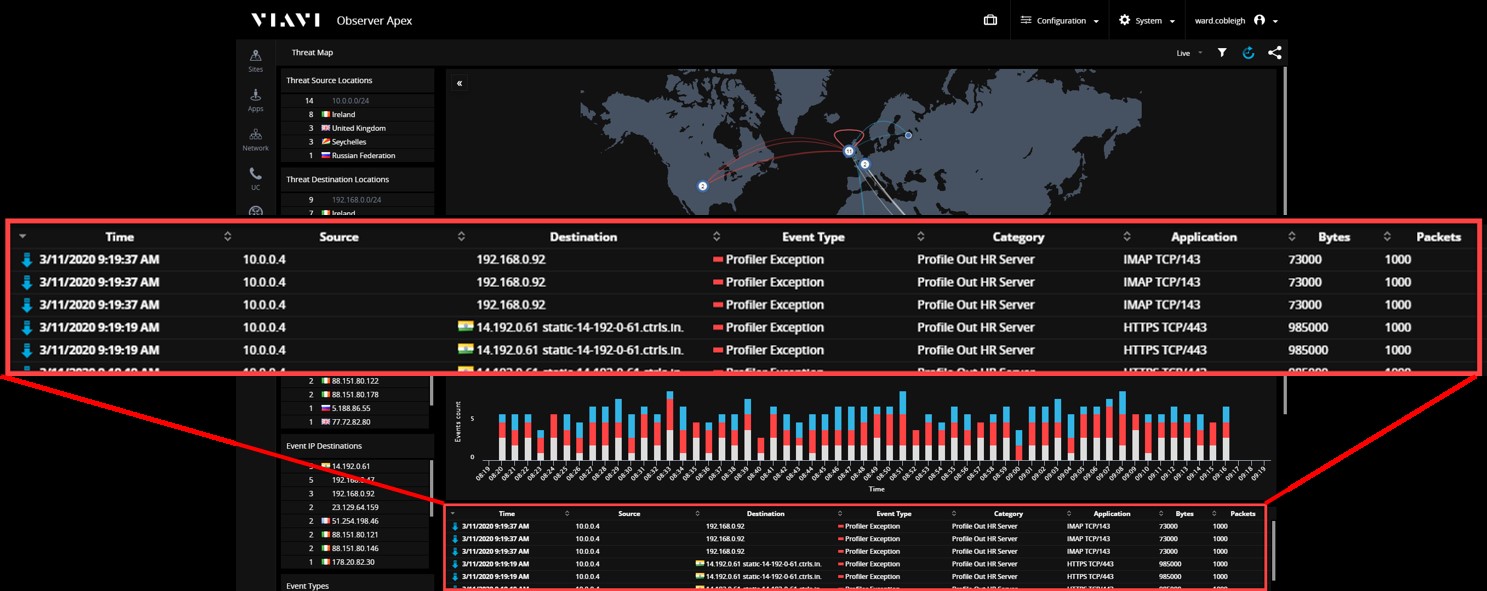
Крок 2: Фокусування
Наша увага швидко переключається на цей один хост - які зв'язки у цього сервера є нетиповими? Дивлячись на події, що описують виключення з очікуваної поведінки, ми бачимо, як часто відбуваються несподівані сесії, і більш детально про те, з ким наш пристрій комунікує і які типи сесій відбуваються.
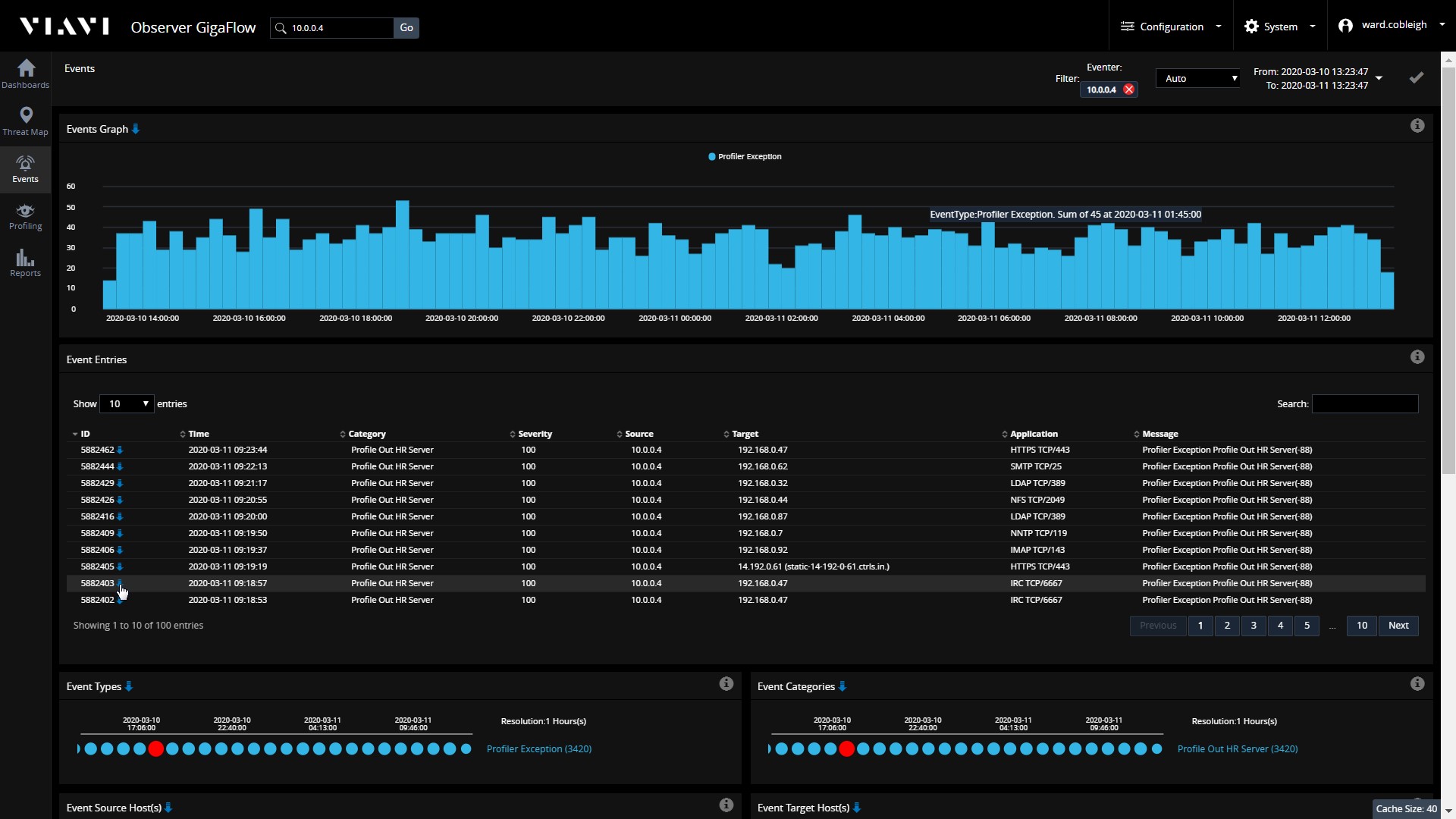
В даному прикладі, припустимо, що особливий інтерес викликає один конкретний пункт - трафік на TCP-порті 6667. З чим взаємодіє наш HR сервер і що саме туди було передано?
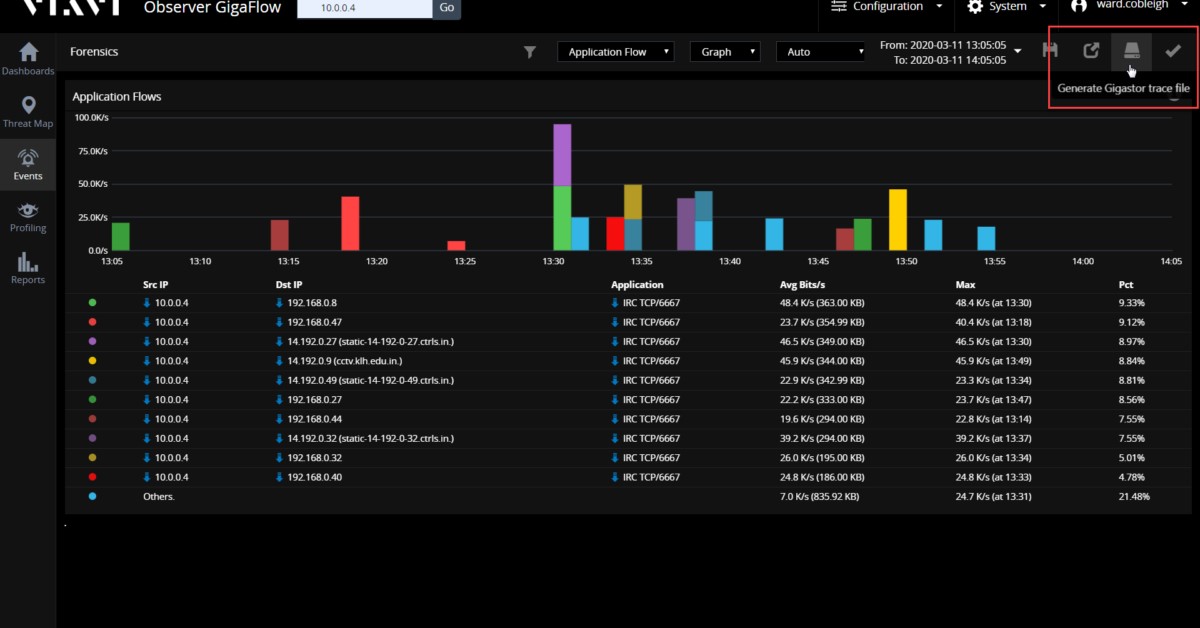
Крок 3: Розслідування
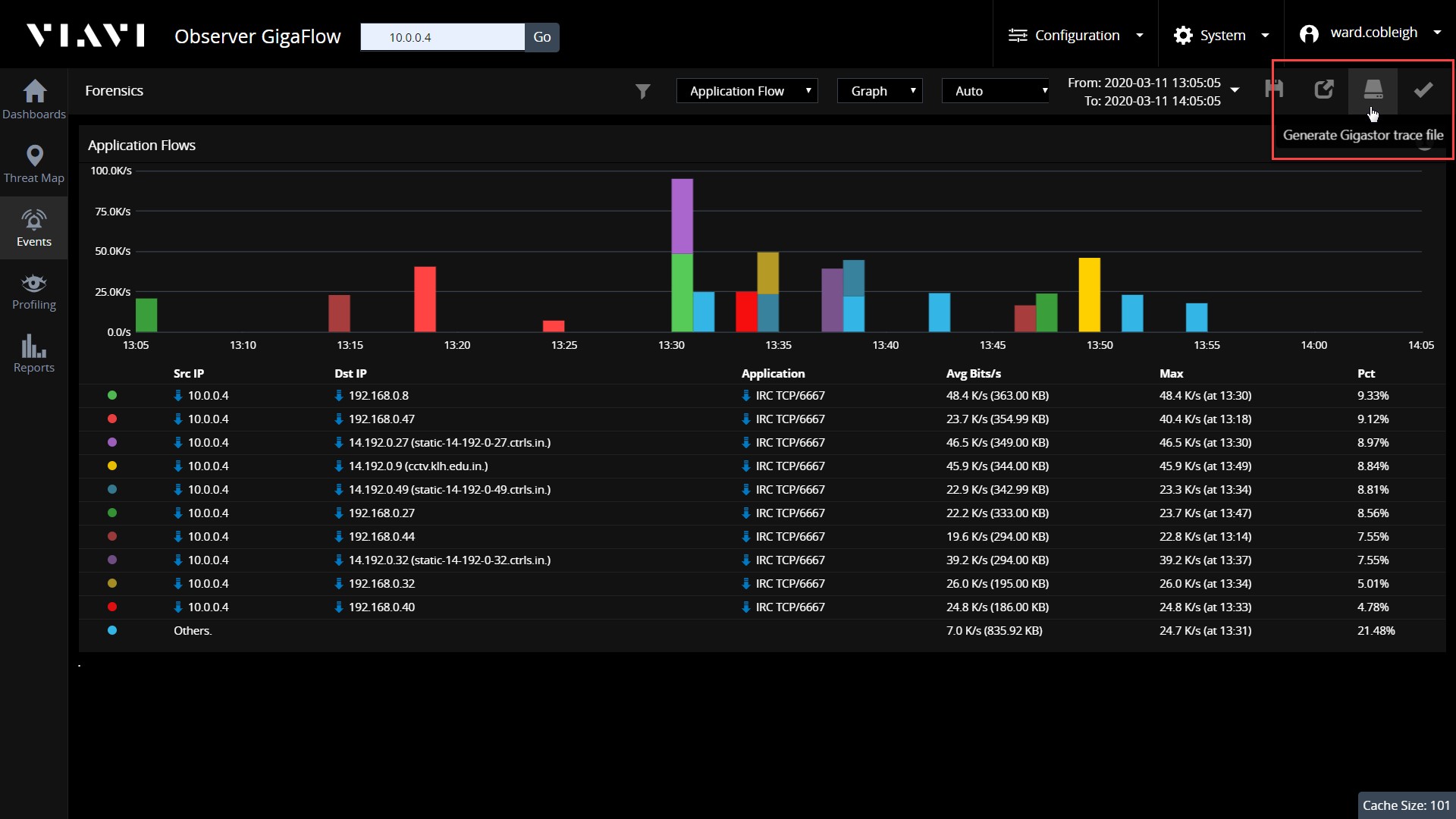
Наш аналіз докладно описує кожну окрему сесію, яка відбулася на сервері з використанням цього порту, період часу, протягом якого ці сесії відбувалися, і обсяг даних, які були передані. Опція експорту дає нам можливість отримувати пакети, які забезпечують кожен біт інформації, що переданий по кабелю. У разі витоку даних, у нас будуть докази, необхідні для того, щоб точно задокументувати те, що було скомпрометовано.
Висновки
Що ми проілюстрували в цьому прикладі:
Важливість автоматичної ідентифікації, отримання та подання дієвої інформації - наш HR-сервер зв'язується з тим, з ким зазвичай не повинен, ми повинні з'ясувати, що відбувається.
Цінність поєднання цієї дієвої інформації з простим, ефективним робочим процесом - ми перейшли від детектування до аналізу в три етапи.
Простота використання - практично будь-який член нашої команди міг побачити і зрозуміти проблему та буквально перейти від карти до пакетів. Тепер аналітик з безпеки або власник пристрою/сервісу має чіткий опис проблеми і «сирі» дані, що необхідні для її вирішення.
Значення синергії спільного використання даних NetFlow (NetFlow, IPFIX, і т.д.) та пакетних даних.
З'явилися питання або потрібна консультація? Звертайтеся!